Example: An order picking process
An order picking process in a warehouse gets calls
for service at an average rate of 8.5 per hour. The average
time to fill the order is 0.1 hours. For analysis purposes
assume both times are exponentially distributed. Analyzing
the system as an M/M/1 queue, the average time in the
queue is 0.5667 hours. An opportunity arises to reduce
the variability of the process for filling orders. The
inventory manager wonders if the change is worth the
cost. |
The set of results for the Non-Markovian
case is smaller than those available for Poisson queues.
This is partially due to the restriction against finite queues
and finite populations, making some results not relevant.
The approximations do not allow the computation of state
probabilities.
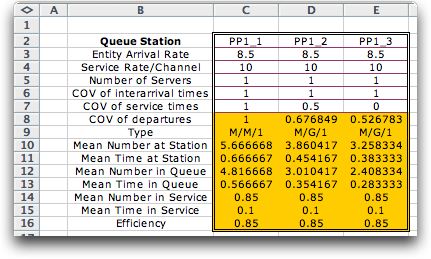
The results for three replications of the queuing model are
shown below. The display was created by the Non-Markov option
of the Queuing add-in. To illustrate the effect of reducing
the variability in the service times, we set the COV of the
service process to 0.5 in the second model and 0 in the third
(no variability). In general the numbers and time in the queue
decrease as variability decreases. Note that with COV of 1,
the distribution is actually Markovian (Poisson process). Thus
we see an M in the type designation when the COV is
1. The G in the type of the second and third
models indicates that the service process has a general distribution.
It is clear from the results that reducing variability in
the service process causes decreased time in the queue. The
mean time in service does not change because that is fixed
by the data and unaffected by the variability. The efficiency
only depends on the amount of work available compared to the
number of servers, so it does not change with variability. |