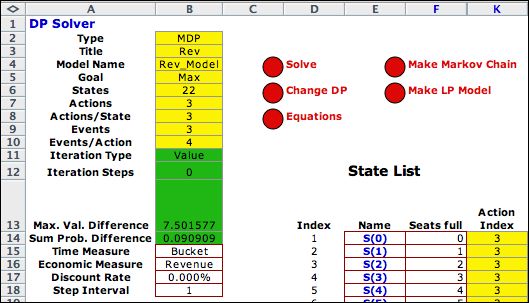
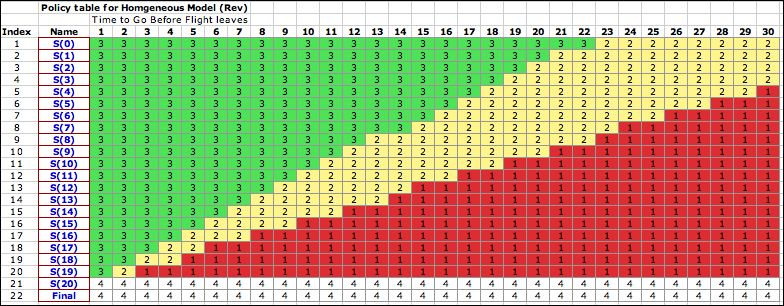
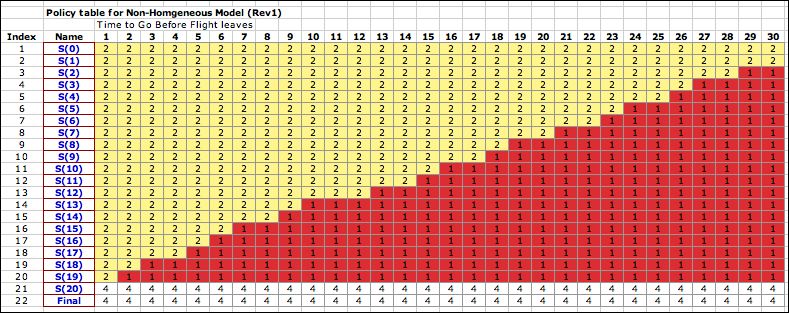
In a more realistic representation,
the model will change over time when different
classes of customers have time-variable arrival rates. Model
Rev1on the example worksheet describes this kind of model. Because
the solver worksheet shows the entire model explicitly, modifications
of the model can be implemented using functions of the step
number. For this case we use the tables below to describe the
variable arrival rates.
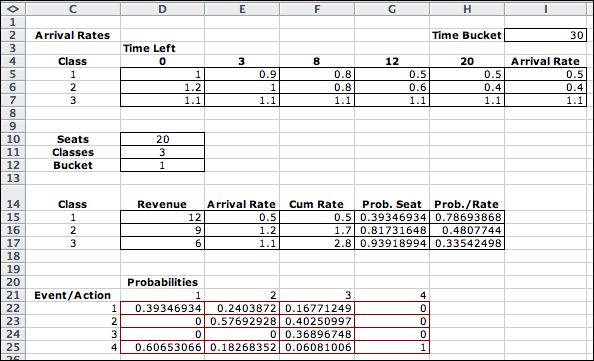
The table at the top shows the arrival rates
by class during five time intervals. The first column (Col.
D, labeled 0) shows the arrival rate for buckets 1 through 2.
The second column shows the arrival rates for buckets 3 through
7, and so on. The current day is in cell I2. This number
is transferred from B12 on the solver worksheet. The current
arrival rates are in cells I5 through I7. They are obtained
from using an Excel Lookup function. The arrival rate is transferred
to the tables below. Ultimately, the bottom table computes
the transition probabilities for each event under each actions.
Action 4 is the null action and event 4 is the null event.
The probabilities are transferred to the transition
probability column on the solver worksheet using the INDEX
function. Now as the iterations progress, the transition probabilities
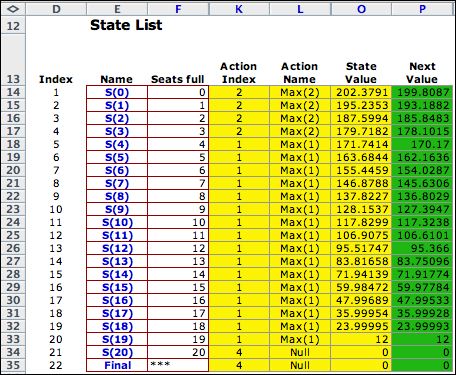
depend on the bucket number. The policy now reflects
the new model. The figure below shows the optimum policy over
the time horizon. It is never optimal to offer the class 3
ticket. |