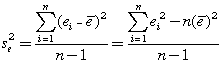| Once a model is selected and data
is available, it is the job of the statistician to find parameter
values that best fit the historical data. We can only hope that
the resulting model will provide good predictions of future
observations.
Statisticians usually assume all values in a given sample are
equally valid. For time series however, most methods recognize
that data from recent times are more representative of current
conditions than data from times well in the past. Influences
governing the data almost certainly change with time and a method
should have the capability of neglecting old data while favoring
the new. A model estimate should be able to change over time
to reflect changing conditions.
In this discussion, the time series model includes one or more
parameters. We identify the estimated values of these parameters
with hats on the parameter notation.
The procedures also provide estimates of the standard deviation
of the noise 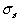 .
Again the estimate is indicated with a hat, .
Again the estimate is indicated with a hat, 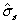 . .
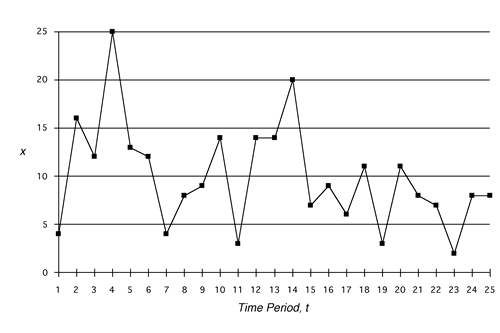
To illustrate these concepts consider the data in Table 1.
Say that the statistician has just observed the demand in period
20. She also has available the demands for periods 1 through
19. She cannot know the future, so the information shown as
21 through 30 is not available. The statistician thinks that
the factors that influence demand are changing very slowly,
if at all, and proposes the simple constant model for the demand
as in Eq. 1.
With the assumed model, the values of demand are random variables
drawn from a population with mean value b. The best
estimator of b is the average of the observed data.
Using all 20 points the estimate is
This is the best estimate that can be found from the 20 data
points. It can be shown that this estimate minimizes the sum
of squares of the errors. We note, however, that first data
point is given the same weight as the last in the computation.
If we think that the model is actually changing over time, perhaps
it is better to use a method that gives less weight to old data
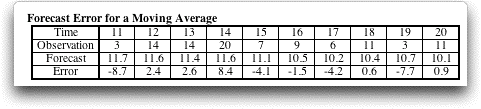
and more to the new. One possibility is to include only later
data in the estimate. Using the last ten observations and the
last five we obtain
The latter two estimates are called moving averages because
the range of the observations averaged is moving with time.
Which is the better estimate for the application? We really
can't tell at this point. The estimator that uses all data points
will certainly be the best if the time series follows the assumed
constant model, however, if the situation is actually changing,
perhaps the estimator with only five data points is better.
In general, the moving average estimator is the average of
the last m observations.
The quantity m is the moving average interval and
is the parameter of this forecasting method. |