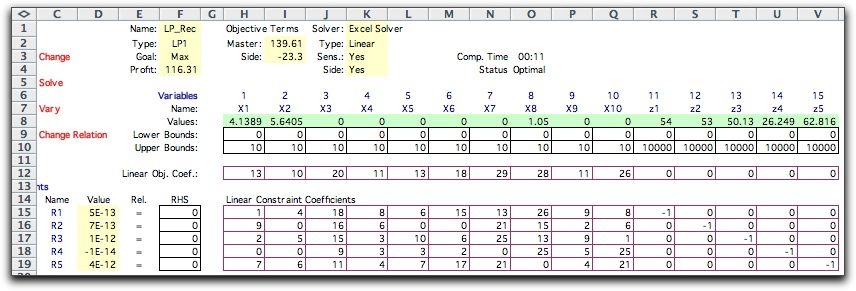
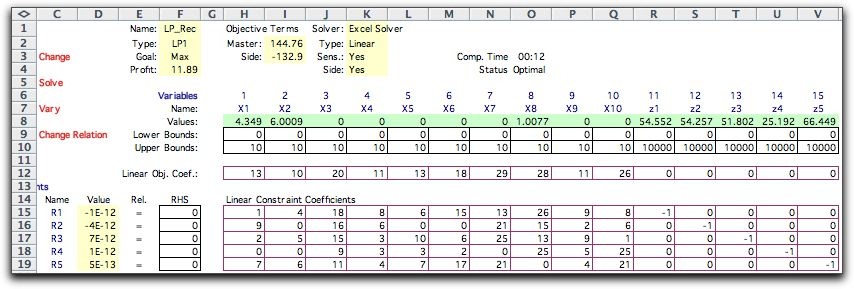
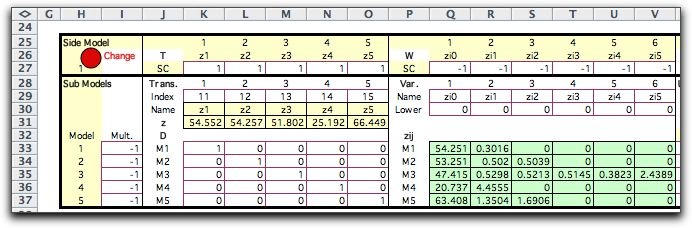
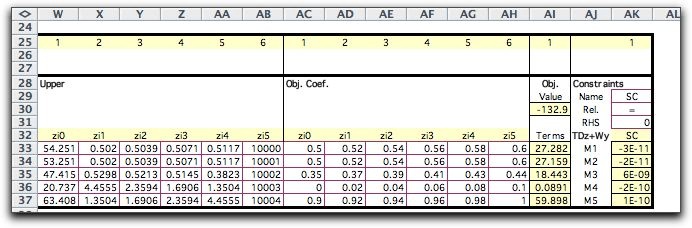
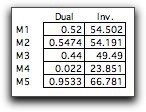
When the distribution of a random variable is continuous rather
than discrete, we will approximate the distribution with either
a discrete distribution or a piece-wise uniform distribution.
In this section we deal with the discrete approximation. We
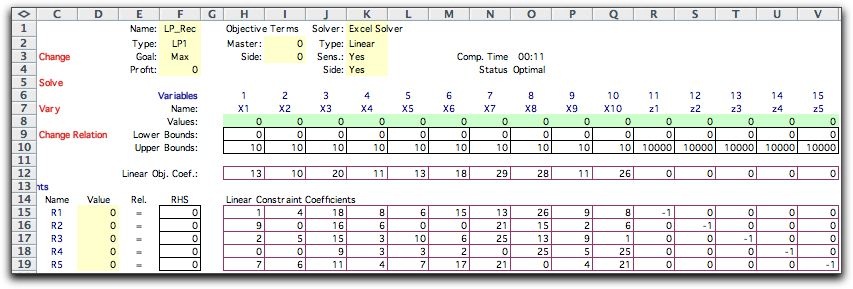
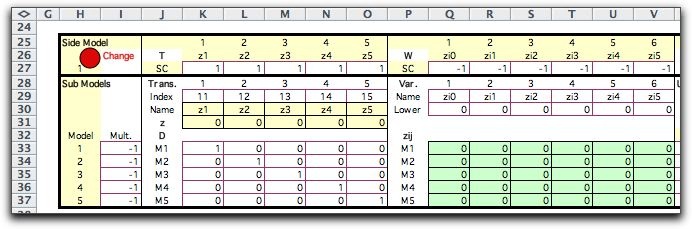
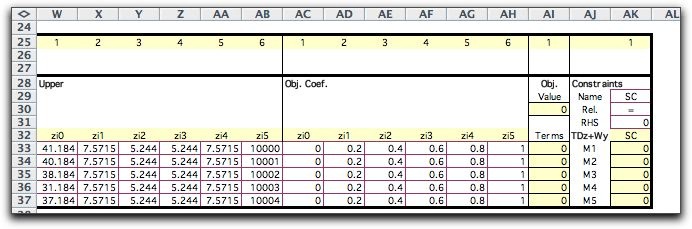
will illustrate this application with a simple-recourse model
of the LP situation used at the beginning of this section.
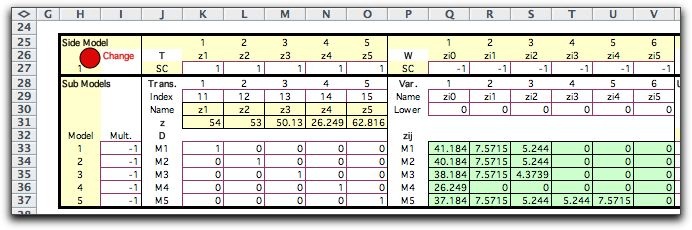
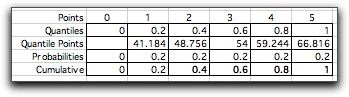
To approximate the continuous distribution we select K+1
quantile values ranging from 0 to 1.

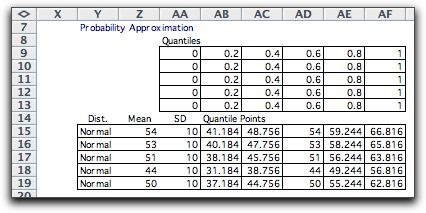
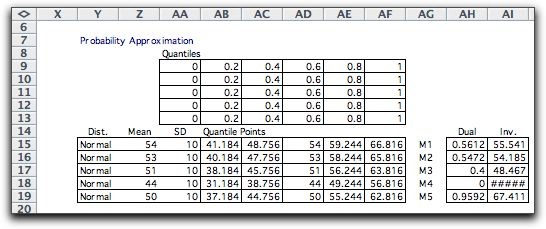
To illustrate, consider a Normal distribution
with mean 54 and standard deviation 10. We divide the probability
range into five intervals using the quantiles: 0, 0.2,
0.4, 0.6, 0.8, 1. The quantile points are computed with the
RV_Inverse function of the Random Variables add-in.
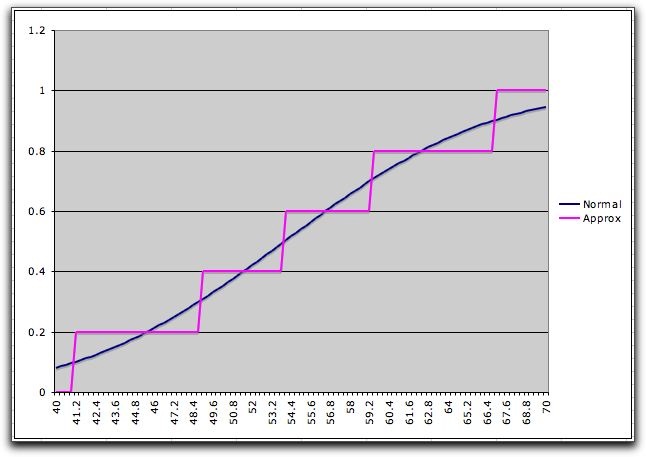
The graph below shows the cumulative distribution
of this discrete approximation along with the Normal distribution.
The construction of the graph shows the steps as ramps, but
the steps are immediate at the quantile points. The approximation
sometimes over
estimates
the
continuous cumulative and sometimes underestimates it.
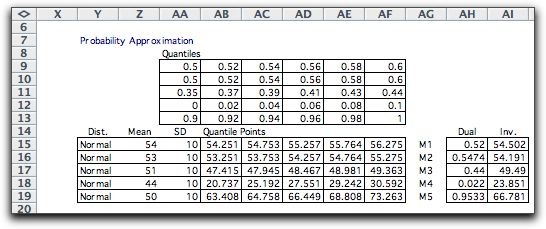
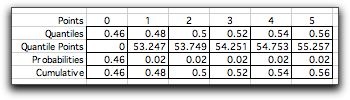
The number of steps and the selection of the
quantiles controls the accuracy of the approximation. The table
below shows a selection of quantiles that emphasizes the range
0.46 through 0.56.
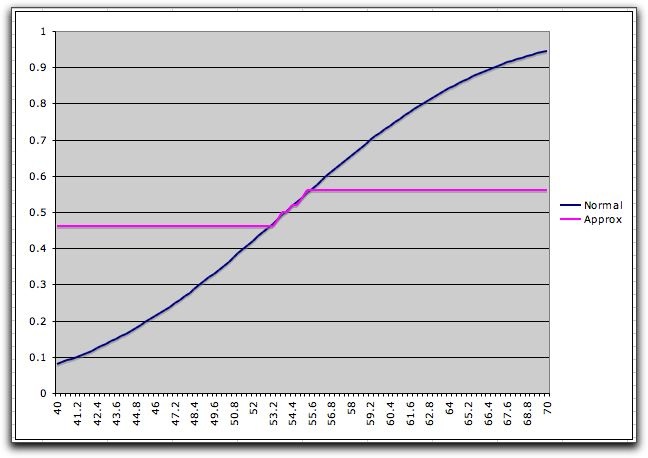
The cumulative distribution is more accurately
represented in this range, while it is not well approximated
outside the range. This feature will have usefulness for the
simple recourse model.
|