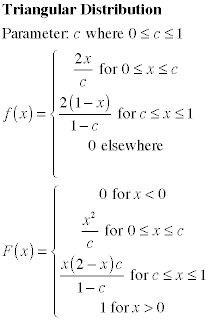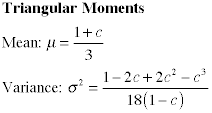Models involving random
occurrences require the specification of a probability distribution
for each random variable. To aid in the selection, a number
of named distributions have been identified. We consider several
in this section that are particularly useful for modeling phenomena
that arise in operations research studies.
Logical considerations
may suggest appropriate choices for a distribution. Obviously,
a time variable cannot be negative, and perhaps upper and lower bounds due
to
physical limitations may be identified. All of the distributions described
below are based on logical assumptions. If one abstracts
the system under study to
obey the same assumptions, the appropriate distribution is apparent. For
example, the queuing analyst determines that the customers
of a telephone support line
are independently calling on the system. This is exactly the assumption that
leads to the exponential distribution for time between arrivals. In another
case, a variable is determined to be the sum of independent
random variables with exponential
distributions. This is the assumption that leads to the Gamma distribution.
If the number of variables in the sum is moderately large,
the Normal distribution
may be appropriate.
In some cases, a particular distribution may chosen because
it best fits the
form of observed data. There are statistical tests to determine
the parameters for the best fit.
Very often, it is not necessary to determine the exact
distribution for a study. Solutions may not be sensitive
to distribution form as long as the
mean and variance
are approximately correct. The important requirement is to represent explicitly
the variability inherent in the situation.
In every case, the named distribution
is specified by the mathematical statement of the probability
density function. Each has one or more parameters
that
determine the shape and location of the distribution. Cumulative distributions
may be
expressed as mathematical functions; or, for cases when integration is
impossible, extensive
tables are available for evaluation of the CDF. For some distributions,
formulas for the moments have been derived.
It is convenient to use named distributions
because it is easier to statistically estimate parameters
rather than entire nonparametric distributions. Also, named
distributions
can more easily be simulated for simulation studies and probabilities
can be computed from the formulas available for named distributions.
We consider a number of named distributions on the following
pages.
Click
on
a link at the left for descriptions and examples. |